from sentence_transformers import SentenceTransformer
import numpy as np
example_animals = ["lion", "tiger", "flamingo", "clownfish"]
# Initialize model
emb_model = SentenceTransformer("BAAI/bge-small-en-v1.5", device="cpu")
# Compute embeddings
example_animals_embeddings = emb_model.encode(example_animals, convert_to_tensor=True).cpu().detach().numpy()Did you ever try to explain what embeddings are to people who have no or only a limited background in machine learning or computer science? I recently tried this in an on-the-fly attempt to explain embeddings with an analogy to animals. While I think I could get the idea across, this analogy has stuck in my mind, and here is version 2.0: Let’s explore how we can visualize the embeddings of terms like “lion”, “tiger”, or “flamingo” to illustrate how a machine learning model understands the meaning of these terms and perceives their semantic relationships to one another.
Here is the plan:
- Let’s start with a technical definition of an embedding.
- This is followed by our final visualization.
- Afterwards we’ll break down the technical definition into more digestible pieces.
In the end, you will understanding exactly how the visualization was created and I hope you will have a more intuitive understanding of the underlying concepts of embeddings. If you feel that the math is to heavy, please just focus on the underpinning ideas.
From Technical to Visualization
Here is the technical definition:
“In the context of machine learning and natural language processing, embeddings are numerical vector representations that capture the semantic essence of text entities, such as words, sentences, or documents. These vectors are typically high-dimensional, often consisting of hundreds or thousands of dimensions, allowing them to encode complex concepts and relationships. The fundamental idea behind embeddings is that texts with similar meanings are represented by vectors that are mathematically close to each other. This representation enables algorithms to process and analyze texts by understanding their underlying semantic content.”
Now, let’s transition from theory to practice. Here are the final visualization which show how our machine learning model “thinks” about various animals, illustrating the concept of embeddings in charts that represent their semantic relationships. Why 2 charts? The left one is the more intuitive one for us humans and the right one illustrates better how the machine thinks.
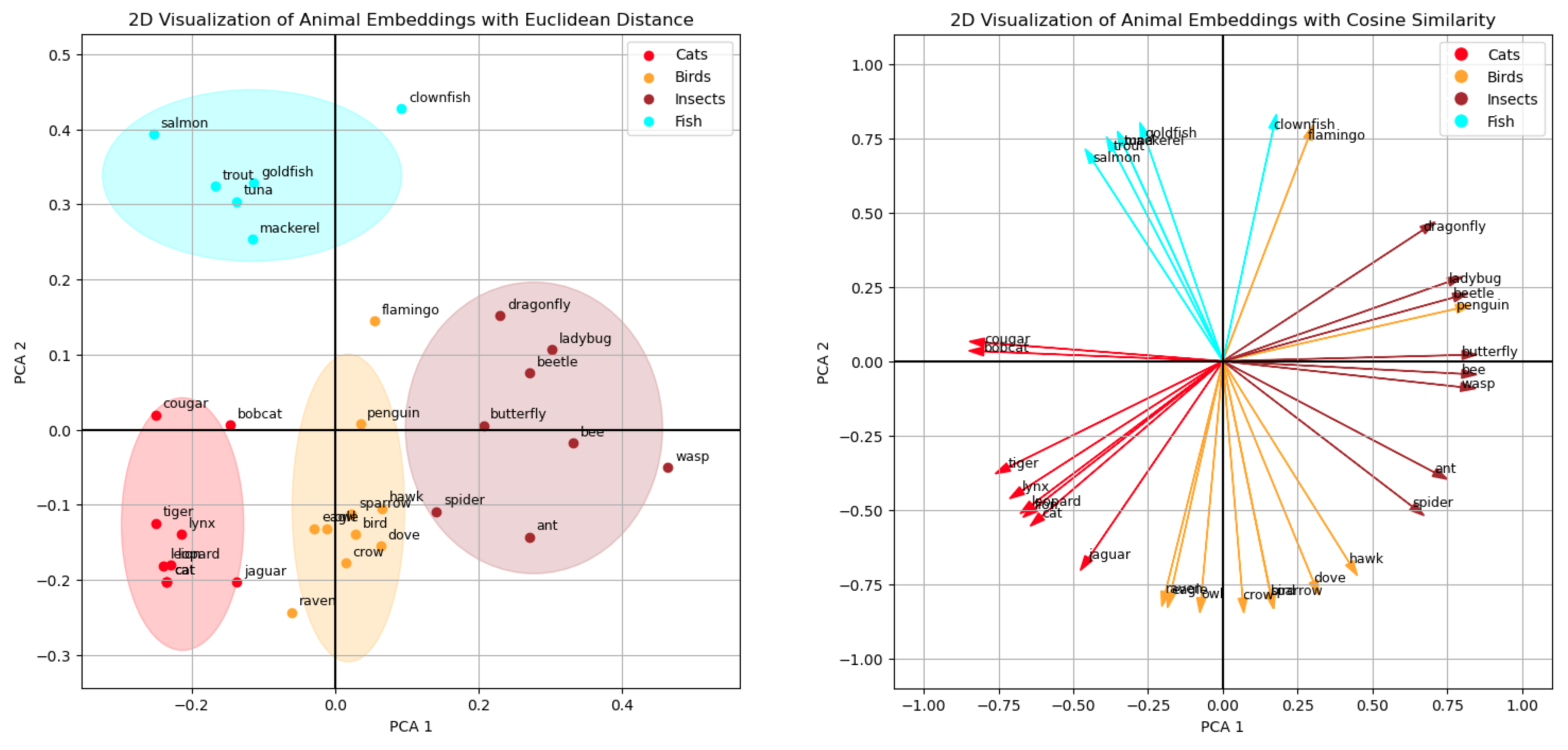
Notes: For readability I hidden most of the code from this blog post. The all the details, please check out the notebook version on Github.
For readability I curated the dataset so that the animal groups are nicely separated. By reducing animals to just 2 numbers, a lot of complexity is lost, but the intent not to create a highly accurate model of the worlds, rather I wanted to present an example which is simple enough so be visualized in 2D to allow you to build some intuition on how embeddings work. Please feel free to experiment yourself in the notebook version on Github.
Visualizing Embeddings with a Small Dataset
Let’s start small and use a dataset with the examples of “lion”, “tiger”, “flamingo”, and “clownfish”.
Embeddings from model
Inspired by the hackers guide by Jeremy Howard let’s use this model to calculate the embeddings via SentenceTransformers
example_animals_embeddings.shape(4, 384)Each word is now represented by a 384-dimensional vector. What does this mean, and where do these numbers come from?
Training an Embedding Model
The model we use is BAAI/bge-small-en-v1.5. BAAI stands for “Beijing Academy of Artificial Intelligence”. Is a private non-profit organization known for its research and development in artificial intelligence technologies. BGE stands for “BAAI general embedding”.
Diving into theit GitHub repo, we can read that this model has been trained in English (and there are Chinese and multi-language models available). It is a general embedding model which has been pre-trained using RetroMAE. Subsequently, it has been trained on large-scale pair data using contrastive learning.
In the RetroMAE pre-training phase, the model has been exposed to vast amounts of text data, such as Wikipedia and BookCorpus to learn a wide range of language patterns, contextual relationships, and the nuances of semantics without specific task-oriented guidance. Contrastive learning has taught the model to pull the embeddings of texts that are similar (positive pairs) closer to each other and push apart embeddings of texts that are dissimilar (negative pairs). It’s through these methods that the model learns to understand and encode the semantic essence of texts into vectors.
Essentially, an embedding is a numerical representation of a text. Unlike hashes, which primarily aim at crating unique representations of stings for retrieval or data integrity, embeddings are designed to capture semantic meaning and relationships between pieces of text. As we will see, embeddings of “lion” and “tiger” are mathematically more similar to each other than “tiger” and “flamingo”, capturing their semantic meaning and similarity.
What is Dimensionality Reduction?
Trying to understand how these 384 dimensions can describe a single word is impossible beyond the trust that these number can magically describe our 4 animals. To gain a more intuitive understanding of embeddings, we can reduce this high-dimensional space to something more manageable, like two dimensions. You can think of this as projecting an object with a torch to the wall, the 3D object is projected to 2D. However, it is important to do the projection in a way which preserves important information. Check out to the following visualization @visualizevalue to the the potential problem.
One effective algorithm for dimensionality reduction is Principal Component Analysis (PCA) which simplifies the data while preserving its most significant patterns.
Note: The remainder of this section explains how PCA works. If you prefer to focus on the results, feel free to skip ahead.
PCA transforms the original high-dimensional variables into a new set of lower dimensional variables, the principal components, which capture the maximum variance in the data. Therefore, the data’s variability is preserved as much as possible. As a result, noise is reduced without filtering out essential information, making it easier to observe patterns, clusters, or relationships that were not apparent in the higher-dimensional space.
Since the math was not 100% self-explanatory to me, I created a separate deep-dive notebook exploring PCA which reduces the dimensionality of a 3D-dataset to 2D, including interactive visualizations. Here is the executive summary which visually takes you through the process:
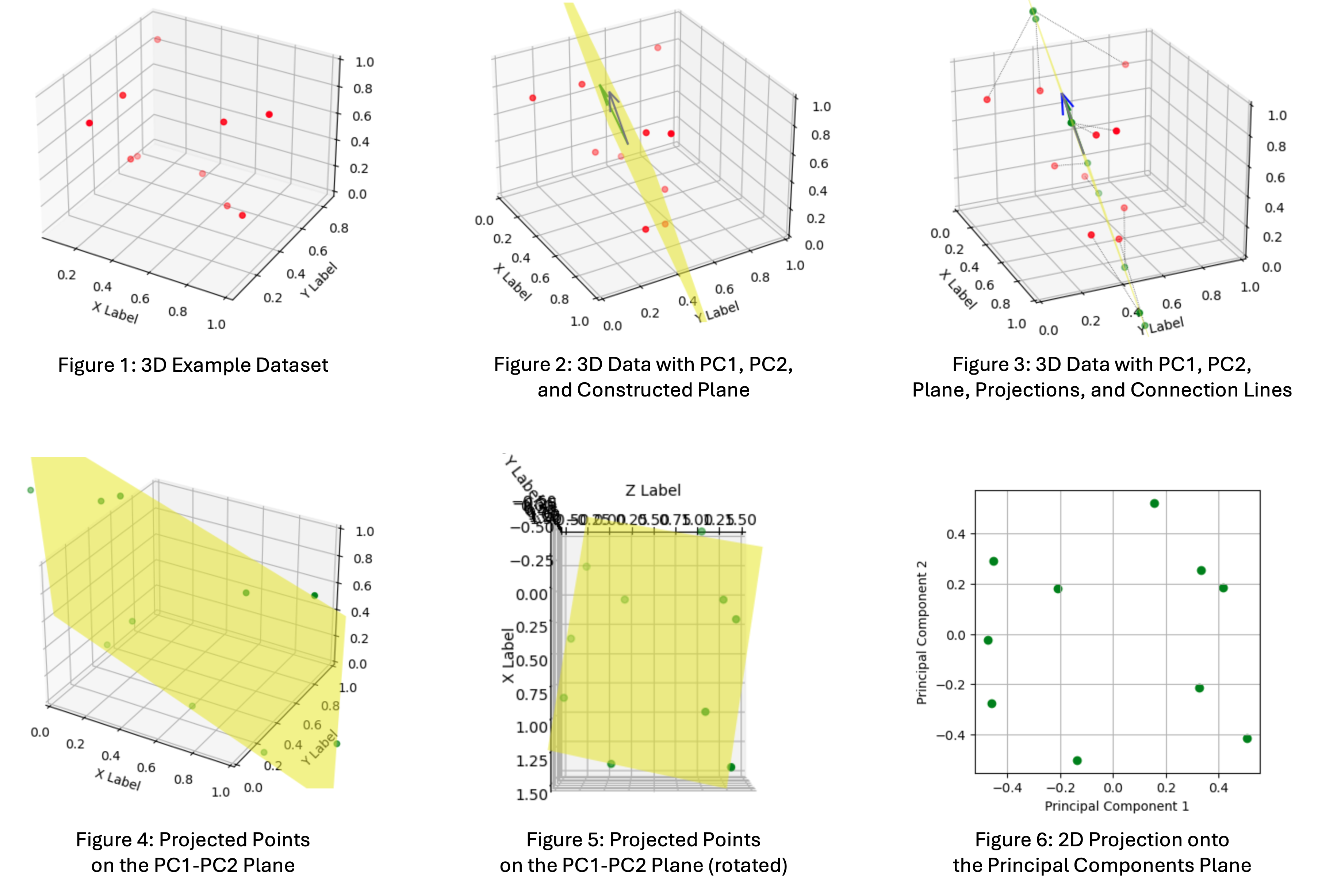
- Figure 1: This is out example dataset with 10 samples of 3D points
- Figure 2: The 2 vectors are the principal components (PC1 and PC2) capturing the maximum variance in the data. We construct a plane from the 2 vectors, the projection plane.
- Figure 3: The 3D-points are projected onto the principal components plane.
- Figure 4: The projected points on the plane in 3D space
- Figure 5: The projected points rotated in a way that we can see the 2D projection in 3D space from above, simulating the reduced dimensionality
- Figure 6: The final 2D representation of the data
With a clear understanding of dimensionality reduction, we can now apply PCA to our example dataset containing “lion,” “tiger,” “flamingo,” and “clownfish” and visualize the outcome.
Applying Dimensionality Reduction
Sklearn offers an easy to consume implementation to apply PCA to out example dataset.
from sklearn.decomposition import PCA
# Apply PCA to reduce to 2 dimensions
pca = PCA(n_components=2)
example_animals_embeddings_2d = pca.fit_transform(example_animals_embeddings)Here is the result, both numerically and plotted in 2D.
example_animals_embeddings_2darray([[-0.35093537, -0.07018732],
[-0.4075373 , 0.02734617],
[ 0.3408063 , 0.40827572],
[ 0.41766608, -0.3654344 ]], dtype=float32)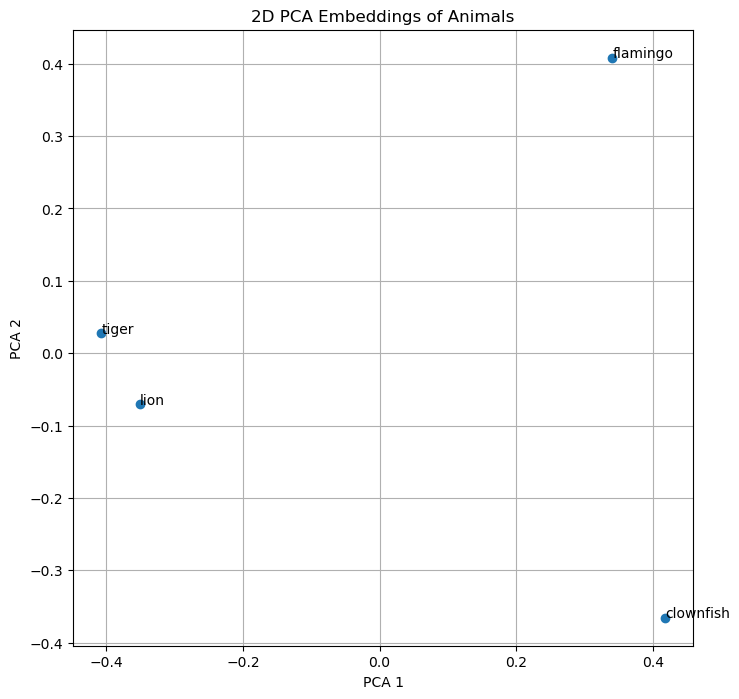
As we can easily see, “lion” and “tiger” are closer to ech other then “tiger” and “flamingo”. After the first visual “proof” let’s explore how we can calculate the distance mathematically because this is how the machine evaluates the similarity of text.
Calculating Distance
What we intuitively do when looking at the chart above is to calculate the so-called Euclidean distance. We see that “lion” and “tiger” are close to each other while the other dots are farther away. While we will do a quick implementation for calculating the Euclidean distances in the next sub-section, it turns out, however, that there are better ways to calculate similarity between vectors. This is why subsequently, we will dive into calculating cosine similarity, followed by a discussion on why cosine similarity is better for calculating the similarity between 2 vectors.
Calculating Euclidean Distance
Here is a visualization of the euclidean distances for our example dataset, confirming our observations.
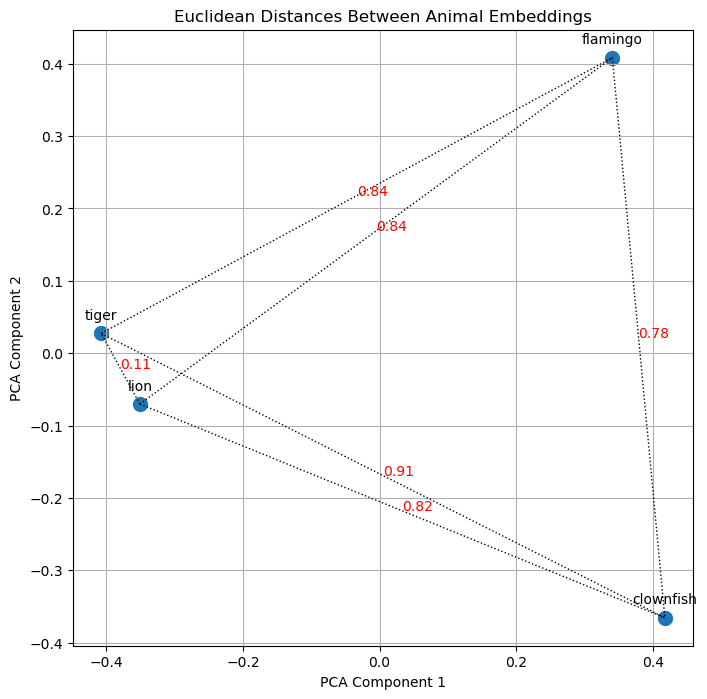
It is also possible to do this calculation in higher dimensionality, but as we discussed above, the orientation of the vectors is more significant than their magnitude. Therefore, let’s turn our attention to cosine similarity.
Calculating Cosine Similarity
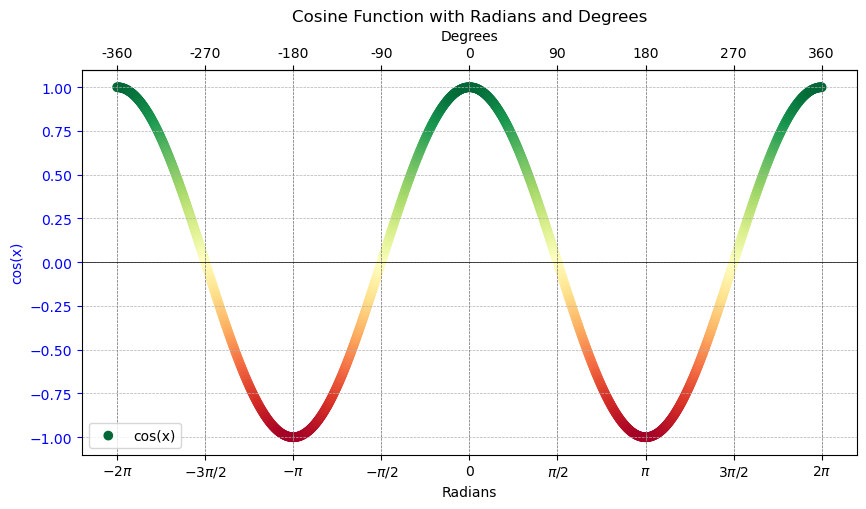
Cosine similarity focuses on the orientation of the vectors with respect to each other without considering their magnitudes (lengths). It measures the similarity between two vectors as the cosine of the angle between them. Vectors pointing in the same direction (regardless of their length) have a cosine similarity of 1, indicating they are very similar. Vectors at 90 degrees to each other have a cosine similarity of 0, indicating no similarity, and vectors pointing in opposite directions have a cosine similarity of -1, indicating completely dissimilar. This principle holds true in higher-dimensional spaces as well. For instance, two vectors in a 3D space will adhere to the same value range for their cosine similarity. Hence, this measure can effectively express the similarity between vectors across any number of dimensions, focusing on how vectors are oriented with respect to each other rather than how far apart they are. This relation is plotted in the following cosine graph, which is colored to indicate similarity.
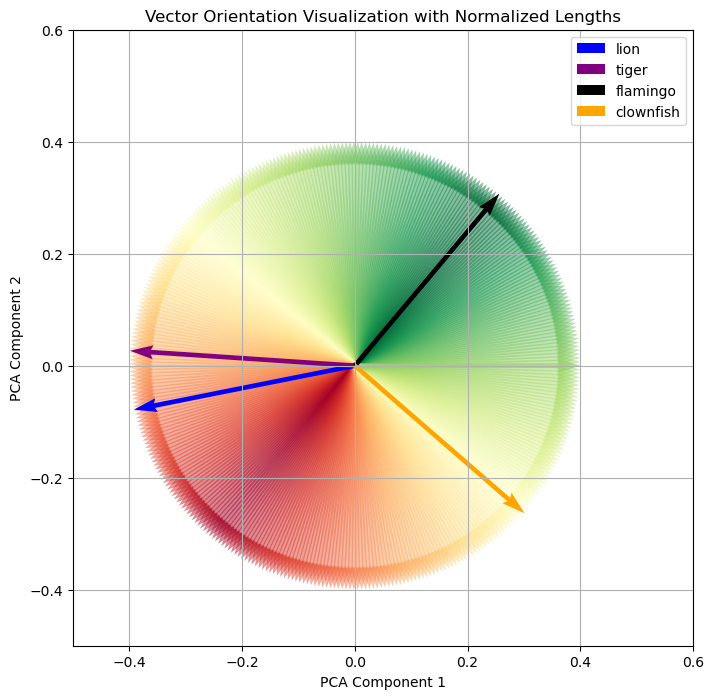
Let’s transfer this our animal example. When thinking in terms of cosine similarity, we need to plot our 4 animals differently. Each animal is represented as vectors, and the magnitude of the vectors are normalized. Additionally, starting with the flamingo, the cosine of the angle in relation to “flamingo” is colored to indicate similarity.
Euclidean Distance vs. Cosine Similarity
When comparing Euclidean distance and cosine similarity, it’s important to consider various aspects that highlight the strengths and limitations of each measure in different contexts. Cosine similarity often proves to be superior in capturing the essence of similarity between vectors, especially in high-dimensional spaces, and offers computational advantages as well.
One reason cosine similarity is favored over Euclidean distance is due to the “curse of dimensionality”: As the number of dimensions increases, data becomes sparse, making all points seem far from each other in the vast volume of high-dimensional space. Consider our example with 4 data points: They can be close together in 2 dimensions, but in a 384-dimensional space, the volume expands exponentially with the dimensions, making the points appear far apart. In 2 dimensions, they can easily be plotted in a relatively small space. In 3D-space, the volume of the cube is the length to the power of 3. In a 384-dimensional space, the volume is the length to the power of 384 - incomprehensible, but it sounds huge! Cosine similarity addresses this by measuring the orientation or directionality of vectors rather than their Euclidean distance, effectively mitigating the impact of dimensionality.
Computationally, cosine similarity benefits from being calculated through dot products (matrix multiplication), which can be efficiently parallelized, offering performance benefits compared to the computations required for Euclidean distance.
Moreover, cosine similarity inherently normalizes its output to a fixed range of -1 to 1, regardless of input magnitude. This normalization makes it easier to compare similarity scores across different contexts, unlike Euclidean distance, which can vary widely in magnitude and makes direct comparisons less intuitive. This bounded range of cosine similarity scores is particularly advantageous, providing a straightforward method to assess relative similarity between pairs of vectors. Furthermore, the -1 to 1 value range aligns well with neural network architectures, optimizing the data input, even though cosine similarity calculations are primarily utilized during inference.
Visualizing Embeddings with More Data
I hope, I did not loose you along the way. Things have gotten a bit technical, but now we are in a good position to create a more complex example which we can nonetheless intuitively understand.
Let’s consider the following data for visualization:
# Dictionary mapping animal groups to colors
group_colors = {
"Cats": 'red',
"Birds": 'orange',
"Insects": 'brown',
"Fish": 'cyan'
}
# Dictionary mapping animals to their corresponding groups
animal_groups = {
"cat": "Cats", "tiger": "Cats", "lion": "Cats", "bobcat": "Cats", "jaguar": "Cats", "leopard": "Cats", "lynx": "Cats", "cougar": "Cats",
"bird": "Birds", "sparrow": "Birds", "raven": "Birds", "eagle": "Birds", "crow": "Birds", "dove": "Birds", "penguin": "Birds", "flamingo": "Birds", "owl": "Birds", "hawk": "Birds",
"ant": "Insects", "beetle": "Insects", "spider": "Insects", "butterfly": "Insects", "bee": "Insects", "wasp": "Insects", "dragonfly": "Insects", "ladybug": "Insects",
"goldfish": "Fish", "trout": "Fish", "salmon": "Fish", "clownfish": "Fish", "tuna": "Fish", "mackerel": "Fish"
}Same as above, we calculate the embeddings using the BAAI/bge-small-en-v1.5 model, and we reduce the dimensionality via Principal Component Analysis (PCA).
from sentence_transformers import SentenceTransformer
import numpy as np
from sklearn.decomposition import PCA
large_pool_texts = list(animal_groups.keys())
# Initialize model
emb_model = SentenceTransformer("BAAI/bge-small-en-v1.5", device="cpu")
# Compute embeddings
large_pool_embeddings = emb_model.encode(large_pool_texts, convert_to_tensor=True).cpu().detach().numpy()
# Apply PCA to reduce to 2 dimensions
pca = PCA(n_components=2)
large_pool_embeddings_2d = pca.fit_transform(large_pool_embeddings)
# Store the 2D embeddings in a dictionary, indexed by animal name
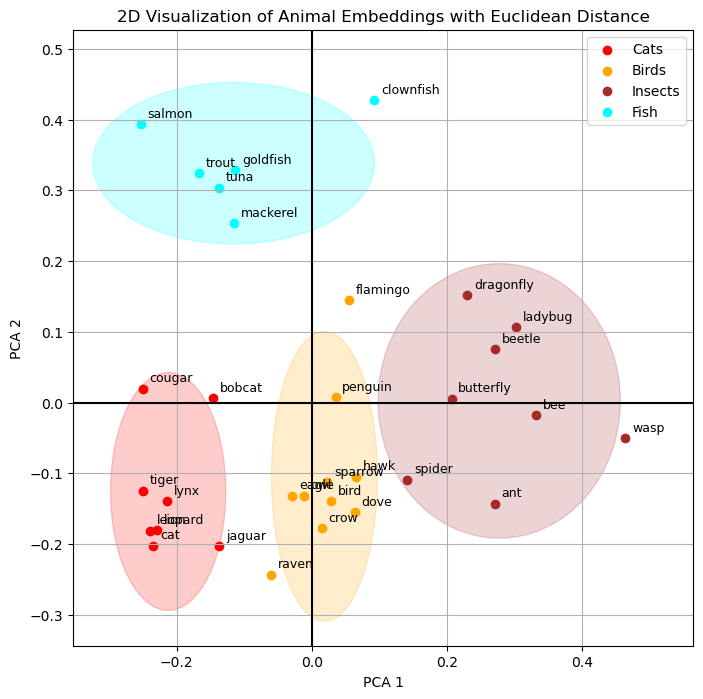
embeddings_2d_dict = {animal: large_pool_embeddings_2d[i] for i, animal in enumerate(large_pool_texts)}Let’s draw the Euclidean distance first by creating clusters of animals. It is important to clarify that these clusters were formed based on the predefined dataset rather than being algorithmically mined from the data. This was a deliberate choice to show that the embedding model has effectively learned to how to group animals. These fairly abstract concepts of “cat”, “bird” or “insect” are connoted in the embeddings, and we can see this because the model converts the strings “lion”, “flamingo” or “ant” into numerical representations which still contain semantic meaning. Creating the embedding therefore is not just a string-to-number conversion (like calculating a hash). It is a lot more nuanced transformation, and it is amazing to see that the embeddings even retain their semantic meaning after we have reduced their dimensionality to only 2 dimensions.
Finally, let’s turn to the cosine similarity, which is the way the machine can even better work with similarity. Personally, I find the Euclidean distance more intuitive in 2D, but thinking back to the comparison of the 2 mechanism, I can also appreciate that the cosine similarity is more universals and computationally more effective. Nonetheless, we can see a similar pattern when plotting the cosine similarities.
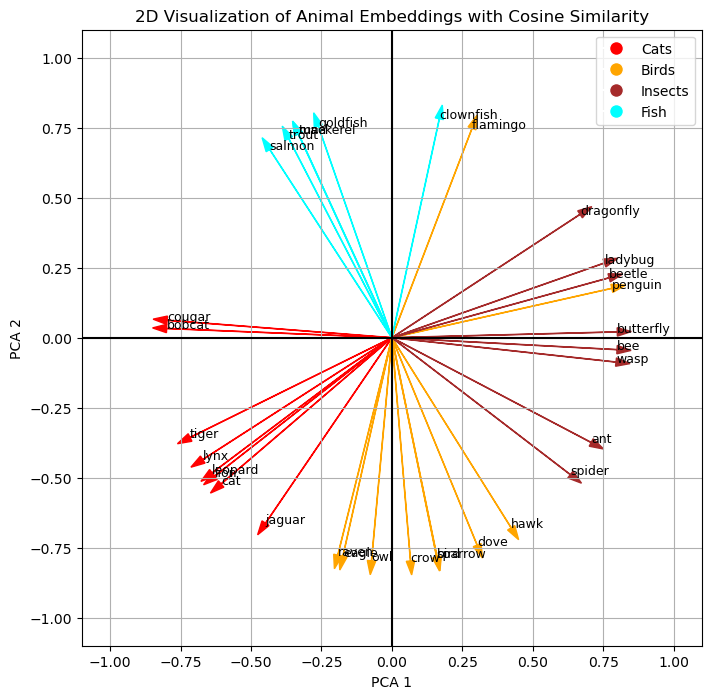
Conclusion
In this blog post, we have explored the foundational principles of embeddings and brought them to life through visualization. Let’s revisit the technical definition of an embedding from the beginning, its meaning should be much clearer now:
“In the context of machine learning and natural language processing, embeddings are numerical vector representations that capture the semantic essence of text entities, such as words, sentences, or documents. These vectors are typically high-dimensional, often consisting of hundreds or thousands of dimensions, allowing them to encode complex concepts and relationships. The fundamental idea behind embeddings is that texts with similar meanings are represented by vectors that are mathematically close to each other. This representation enables algorithms to process and analyze texts by understanding their underlying semantic content.”
We have seen how embeddings are numerical representations of text, in the example we used numerical representations of animals (“lion”, “tiger”, “flamingo”, “clownfish” etc.) which contain semantic information. We have reduced the dimensionality of the vectors with 384 dimensions to only 2 dimensions to plot the 2D vectors. We have visually seen that the semantic information of the data remained intact even in the reduced vectors because the points representing the animals formed the clusters of the dataset (“Cats”, “Birds”, “Insects”, “Fish”) we did not show to the embedding model. This proximity of the points (their Euclidean distance) represents their semantic relation to each other. Finally, we discussed and plotted the cosine similarly which has advantages for calculating vector similarity in machine learning use cases.
In closing, regardless of how complex the math might seem, I hope you have gained a more intuitive understanding of embeddings and the underlying concepts they are built upon.