sequenceDiagram
participant DP as Data Provider
participant TP as Training Pipeline
participant Human as Human Annotator
%% Step 1: Language Model Pre-Training
Note over DP,TP: Step 1: Language Model Pre-Training
DP ->> TP: Provide Large General-Domain Corpus for Pre-Training
TP -->> DP: Return Pre-Trained Language Model (Foundation Model)
%% Step 2: Instruction Tuning
Note over DP,TP: Step 2: Instruction Tuning
DP ->> TP: Provide Instruction-Focused Corpus for Fine-Tuning
TP -->> DP: Return Instruction-Tuned Language Model (Assistant Model)
%% Step 3: Reinforcement Learning with Human Feedback (RLHF)
Note over DP,Human: Step 3: Reinforcement Learning with Human Feedback (RLHF)
DP ->> TP: Prompting Instruction-Tuned Language Model
TP ->> Human: Provide Generated Outputs for Feedback
Human ->> TP: Provide Feedback on Model Outputs
TP -->> DP: Return RLHF-Tuned Language Model (Chat Model)
Large Language Models (LLMs) like ChatGPT have become invaluable tools for many of us. But what lies beneath the surface of these sophisticated models? How have they been trained to deliver such a seemingly magical experience? In this blog post, we will conceptually explore the training methods used for LLMs and dive into some details. In line with Jeremy Howard’s Hackers’ Guide to Language Models [1], our journey begins with the foundational ULMFit Paper [2], which introduced a three-step approach to language model training. After a brief detour into tokenization, we will examine how this three-step approach is implemented today by analyzing the LLaMA papers and other sources. By exploring the different phases, you will gain a deeper understanding of the inner mechanics of large language model training and build intuition on how these models learn a broad range of skills by simply predicting the next token in a sequence of tokens. In conclusion, we will see that today’s large language model training involves at least four steps, with an optional fifth step.

The ULMFiT Paper
Today’s approach to training large language models dates back to the 2018 ULMFit Paper [2] by Jeremy Howard and Sebastian Ruder. They describe a transfer learning approach to natural language processing (NLP). Although the paper’s intention was to train a classifier, such as generating ratings from an IMDb movie review, the approach is remarkably similar to training a large language model today.
The ULMFiT method consists of three main steps:
Pre-Training: The language model is trained on a large corpus of text to learn the essence of language, its structure, the meaning of words, and real-world concepts. In the ULMFiT paper, they used the Wikitext-103 dataset containing about 100 million tokens of Wikipedia text. Back in the days, this was considered to be large 😉. This phase is not task-specific, instead, it teaches the model general language understanding. Today, this step is still the foundation for training large language models, but the models are trained on significantly larger and more diverse datasets.
Fine-Tuning: In this phase, the model is fine-tuned on domain-specific data, such as movie reviews, to learn the specifics of the domain. Originally, this was done using discriminative fine-tuning, where different layers of the model are trained with varying learning rates. This fine-tuning phase conceptually persists in modern language model training, although the training methods have changed to become instruction tuning.
Classifier Fine-Tuning: Finally, the model is trained for the specific task, such as classifying movie reviews, using labeled examples. Originally, this was done by adding some final layers to the model and carefully freezing/unfreezing the pre-trained model to prevent it from forgetting its pre-training. Again, this additional fine-tuning step still exists in today’s language model training, but this has become Reinforcement Learning by Human Feedback (RLHF) which fine-tunes a model according to human preference.
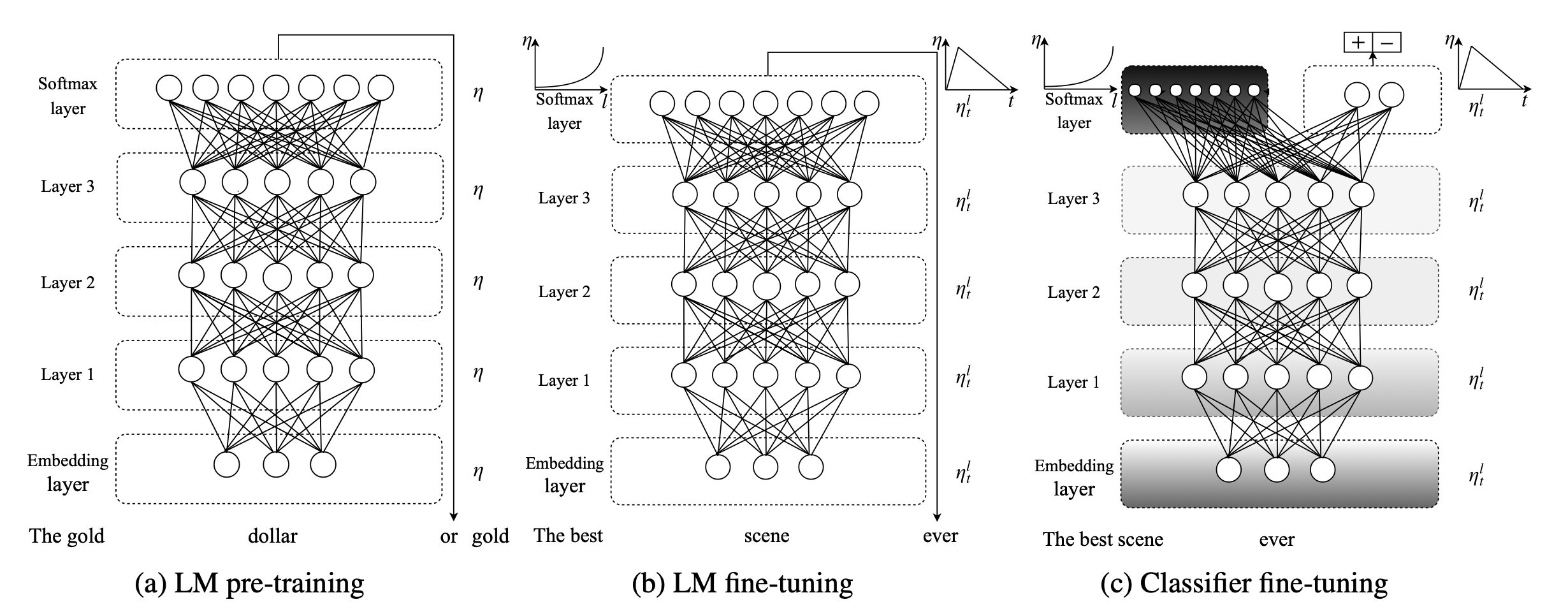
The 3 Steps of Training Large Language Models
While the techniques have evolved, training a large language models today still fits a 3-step approach of pre-training, followed by two fine-tuning steps: Instruction tuning and reinforcement learning by human feedback (RLHF). When you read through the papers or announcements of recent LLMs (ChatGPT or Llama3), you will often find references to pre-training and fine-tuning, but many details are hidden between the lines about the process. The Llama2 paper [3], not surprisingly due to Meta’s open-source approach, is one of the best resources to read about the process. Andrej Karpathy’s video Intro to Large Language Models [4] also excellently explains the different stages of the training process. Let me break it down for you.
While the 3-step approach is exactly what happens when training an LLM, we need to step back and talk about tokenization first. Since computers / computer scientists start counting at 0 and since the tokenization happens before pre-training, let’s call it “step 0”.
Step 0: Tokenization
You often hear the phrase that “LLMs are trained to predict the next word of a sentence”. This is a convenient simplification we can easily relate to, and we will use this simplification for the rest of this blog post, but let’s face reality for a few sentences: Today’s LLM actually thinks in terms of tokens which can either be letters, a combination of letters or whole words, maybe something like a syllable. Tokens are the building blocks, the atoms of the LLM-generated language, but they also determine the network architecture and they are the currency of LLMs. After all, LLMs API are usually billed based on tokens.
For the purpose of this blog post, we need to understand that the vocabulary of a tokenizer, i.e. the individual tokens, is learned from data. Many tokenizers use Byte Pair Encoding (BPE) to determine which combination of letters is a token. Simplistically said, BPE starts with a vocab consisting of just letters. Then it finds the most common combination of letters and assigns it to a new token. This process is repeated until the size of the vocab (a pre-determined number) is reached.
The vocabulary of a tokenizer determines the capabilities of a model, for example, by including or excluding characters other than the Latin alphabet, an implicit decision about language support is already made. Additionally the vocabulary of the tokenizer is an indicator for how efficient an LLM can be in a language because there is a tradeoff between vocab size and computational efficiency. Very small vocabularies (only letters, for example) are similarly inefficient as having millions of tokens (like all entries of all encyclopedia of all supported languages).
The composition of the vocab already contains information on how language is structured, because the most frequent words get their own tokens. Infrequent or combined words are split up in more than one token or even only letters. The following illustration generated via Tiktokenizer show, for example, how “token” is a token, but “tokenization” consists of 2 tokens.
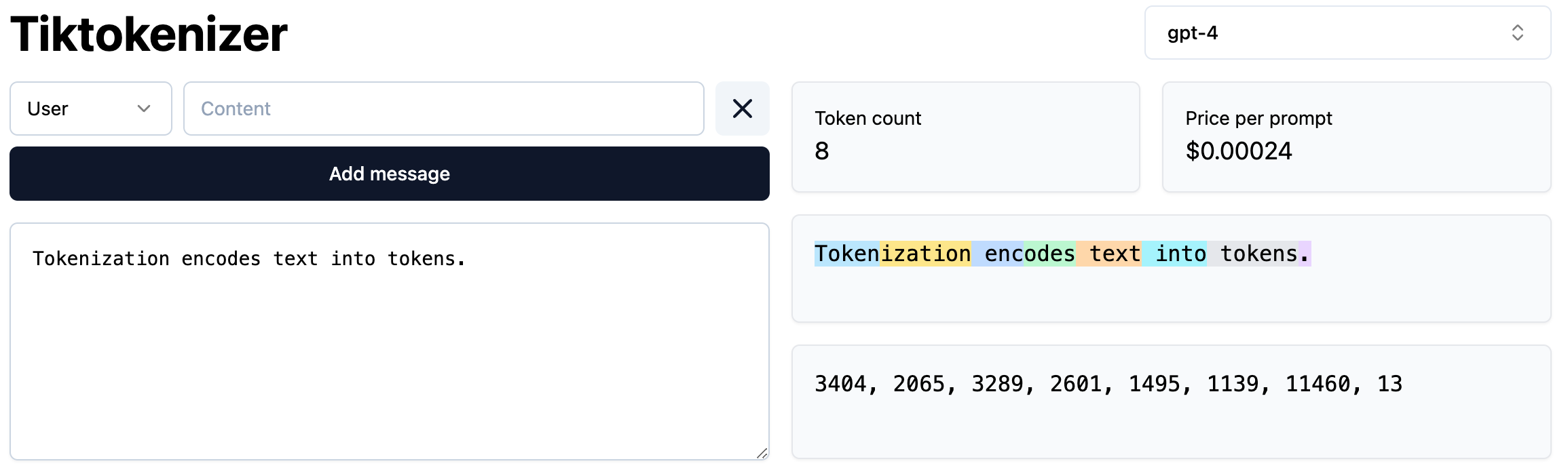
Tokenization, however, is a process which needs to be finished before the LLM is trained, because the LLM only learns on tokenized data. Additionally, the size of the vocabulary also influences the network architecture, because for every token of the vocab an embedding is learned during LLM training. These embeddings are numerical representations of the tokens which contain semantic meaning. This is easier imagined for words, and I explained embeddings and their meanings in detail in this blog post.
For the remainder of this blog post let’s stick to the convenient lie [5] that LLMs are next word predictors (not next token predictors) because it makes thinking about LLM training more intuitive. Before we move on to pre-training, one final note on tokenization: The video Let’s build the GPT Tokenizer by Andrej Karpathy [6] is very accessible for learning more about tokenization.
Step 1: Pre-Training
The first step in training large language models is pre-training. During pre-training, the model “reads” vast amounts of text, in a self-supervised way to learn the following:
- Grammar and Syntax: Understanding the rules and structure of language.
- Semantics: Learning the meanings of words and phrases in various contexts.
- World Knowledge: Accumulating general information about the world, which is embedded in the text.
This is easily said, but what happens under the hood, i.e., in the net? While the learning mechanisms of babies and LLMs function in completely different ways, you could nonetheless say that LLMs learn about language like children. Children have highly adaptive brains, but they initially know nothing about language. By paying attention to the world around them (and receiving instruction and correction), they learn the meanings of words, the structure of sentences, and grammar — no textbook required. Similarly, LLMs begin with randomly initialized neural networks and are exposed to vast amounts of text. They use mechanisms like the transformer architecture with its attention mechanism to learn grammar and syntax, semantics, and gain world knowledge. Let’s unpack the various aspects of LLM pre-training in the following sections.
How large is “vast”?
When we say that during pre-training, the model “reads” vast amounts of text, how large is “vast” actually?
Let’s try a human-centric comparison: How much can a human read in a lifetime compared to the training set of an LLM? For a first reference point, let’s calculate the amount of text a human could read in a lifetime:
Code
# Constants
hours_per_day = 2
days_per_year = 365
years = 50
reading_speed_wpm = 250
average_book_length_words = 85000
# Calculate total number of hours spent reading
total_hours_per_year = hours_per_day * days_per_year
total_hours = total_hours_per_year * years
# Calculate total number of words read
total_minutes = total_hours * 60
total_words = total_minutes * reading_speed_wpm
# Calculate total number of books read
total_books = total_words / average_book_length_words
# Calculate total number of tokens read (1 token per 0.75 words)
tokens_per_word = 1 / 0.75
total_tokens = total_words * tokens_per_word
# Print the results with formatted numbers
print(f"Using the parameters defined in the code, a human might read for {total_hours:,} hours in a lifetime.")
print(f"To put this into numbers, a human would have read:")
print(f" - {total_books:,.2f} books")
print(f" - {total_words:,} words")
print(f" - {int(total_tokens):,} tokens")Using the parameters defined in the code, a human might read for 36,500 hours in a lifetime.
To put this into numbers, a human would have read:
- 6,441.18 books
- 547,500,000 words
- 730,000,000 tokensLet’s compare this to the training data of a large language models. The following table contains data from Wikipedia with some additions. It turns out that even the “ancient” GPT-2 was trained on almost an order of magnitude more tokens than a human can read in a lifetime:
| Model | Release Date | Parameters | Training Data (tokens) | Multiplier (compared to human) |
|---|---|---|---|---|
| Human | Ongoing | Incomparable | 730 million | 1x |
| GPT-1 | June 2018 | 117 million | 5 billion | 6.85x |
| GPT-2 | February 2019 | 1.5 billion | 10 billion | 13.70x |
| GPT-3 | June 2020 | 175 billion | 300 billion | 410.96x |
| GPT-4 | March 2023 | Estimated 1.5 trillion | unknown | unknown |
The Llama Paper [7], gives even more insights as llama was trained on publicly available data. The following table shows the model training data, and converting this into tokens, the paper states that “LLaMA-33B and LLaMA-65B were trained on 1.4T tokens. The smaller models were trained on 1.0T tokens.”
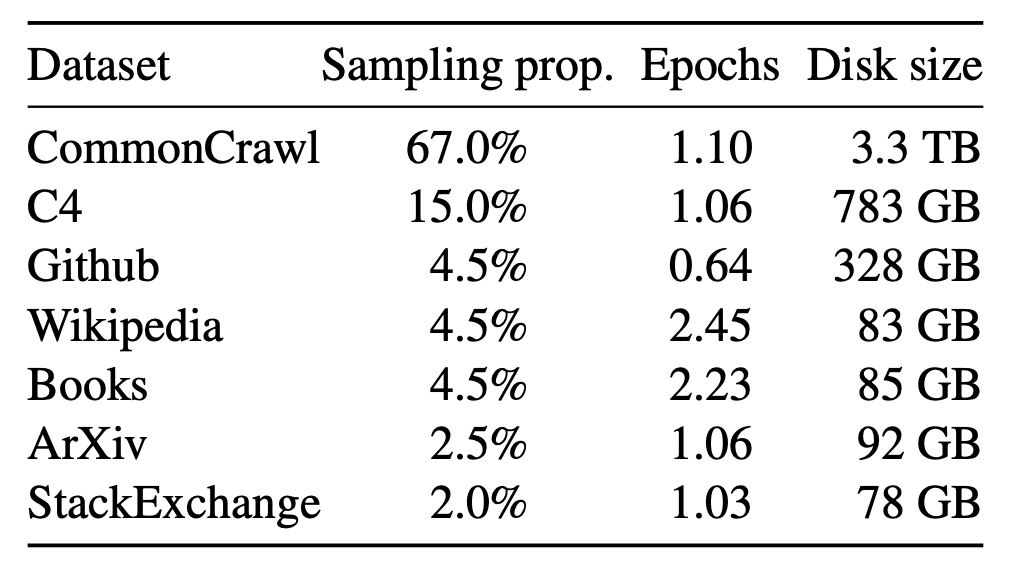
State-of-the-art LLMs have therefore seen several orders of magnitude more text than the average human, but what does this actually mean? How can LLMs learn from just reading text?
What does “reading” mean?
When we say that a large language model reads text, that is oversimplifying the process. Instead, the training pipeline samples batches from the training set text, and the size of this batch is the context window of the large language model. The text is therefore split up into these batches, each of which is used to train the model on next word prediction. Conveniently, one batch of text can be turned into many training examples by masking different parts of the text [8]. Typically, it is performed like this:
- Batch: “The cat sat on the mat”
- Training example 1: “The cat sat on the …”
- Training example 2: “The cat sat on …”
- Training example 3: “The cat sat …”
- Training example 4: “The cat …”
- Training example 5: “The …”
For each of these training examples, the model attempts to predict the next word. Although it may not be obvious at first sight, a model needs extensive knowledge to make an accurate prediction. First of all, it needs some understanding of grammar. For example, words like pronouns (“he”, “she”, “it”) would be poor predictions, and while adjectives (“beautiful”, “hard-working”) might make sense in some contexts, they are not ideal here. We are looking for a noun, but not just any noun, “sky” or “idea” would be poor choices. Instead, the model needs to have knowledge about the world to determine that we need a physical object associated with cats (implying that the model can understand what a cat is) and the surrounding context. Therefore, words like “couch”, “bed”, or “mat” are likely candidates. As you can see, the model needs to know quite a bit about the world to make a good prediction.
Conveniently, the actual word the model should predict is known, allowing the model to learn in a self-supervised way by evaluating its predicted word against the actual masked word. The prediction is not just a single word but a probability distribution of all the words in the model’s (i.e. the tokenizer’s) vocabulary. The most likely word in this distribution is chosen as the prediction, check out this video from 3Blue1Brown [5] to see it in action.
When calculating the loss (via cross-entropy loss), the model therefore receives nuanced feedback on its performance rather than just a simple right or wrong answer. This feedback helps the model understand how close its prediction was to the actual word, and it can adjust its internal parameters accordingly. This adjustment process, known as gradient descent, updates the model weights via back-propagation to improve future predictions. This means that all the neurons in the many layers of the neural network receive feedback on how well they contributed to the final prediction. This way the model not only learns to predict the exact next word but learns to understand the context and semantics of the language better.
For example, if the model predicted “number” instead of “mat,” the loss would be high, and parameters in the network would receive more significant updates compared to a semantically better prediction like “couch.” In both cases, however, the model learns from its predictions. As the gradients flow back, more semantic meaning is baked into the token embeddings. Additionally, the key and query matrices of the transformer architecture learn about how words are related to each other, enhancing the model’s understanding of language and its semantics.
Summing up this section, “reading” is a lot more than just acknowledging the text. It essentially dissects the text into training examples, and the model learns by trying to predict masked words in the texts.
Learning Semantics, Grammar and Syntax, and World Knowledge
What exactly happens within the different matrices during gradient descent is basically impossible to grasp, but can we build some intuition on how an LLM can acquire knowledge even though it primarily functions as a next word predictor? Let’s start with the raw embeddings of each token. Even when carefully trained, the meaning of each token remains ambiguous, even when we think in terms of words. A “model,” for instance, can refer to a machine learning model, a fashion model, or a toy.
The transformer architecture and the attention mechanism allow the tokens to “communicate” with each other. Through the key and query matrices, the model learns which words/tokens are more related to each other. However, we should not think about this in the way of a look-up table, but rather that the patterns like adjective-noun relations are learned by the model so that during inference the respective embeddings can be updated. Let’s take the context of “machine learning model”: During training time, the model has learned that some words in certain locations are likely to imprint additional meaning on other words. This knowledge is baked into the LLM so that at inference it can pass on the meaning of “machine learning” to “model”.
The model does not only learn how to update the semantics, but also an understanding of the structure of language starts to emerge. For example, a large language model learns to use the third person “s” when it sees many sentences like “Tom likes chocolate.” However, the LLM does not explicitly learn the rule itself (“In the present tense, add an”s” to verbs when the subject is a singular third person (he, she, it)“). Instead, the model learns to mimic the pattern of the training data by selecting the most likely form of the verb”to like” during inference.
The more training data the model is exposed to and the larger the neural network, the more implicit knowledge the model can store. By reading about chocolate, the model learns that it is usually brownish, contains cocoa and sugar, tastes good, and perhaps some chocolate brands. This is how a model can store knowledge. Again, this is not a look-up table, but the model learns the gestalt of chocolate. Think of it like reading the Wikipedia article about chocolate: Neither you nor the LLM can recite the article word-for-word afterwards, but both you and the LLM will have learned something about chocolate. Andrej Karpathy calls this a “lossy compression”, and this is one factor why models hallucinate: They simply pick the most likely next word/token based on what they have read and understood about chocolate. We should not think about the learning process for LLMs as a deterministic process like filling a bunch of database tables with facts, but it is a much softer and subtle process, just like our human learning experience.
Therefore, an LLM can easily continue a prompt like “Chocolate is made of …” based on everything it has learned, and it will likely produce a good answer. However, there is a risk that some information may be inaccurate. As we move into the next training phase, we will get to know strategies on how these risks can be minimized.
Before we move on to the next training stage, we need to talk about the term “Foundation Model”, which is used to describe a model delivered by pre-training. Foundation models are not the models which are used by ChatGPT. Rather, a foundation model can become a chat model, but we still need 2 more training steps (Remember the 3-step training approach!). Nonetheless, the terminology can be confusing because you can select “GTP-3.5” or “GPT-4” as a model in the OpenAI-UI. This, however, only means that the Chat Model you use has been trained on the respective foundation model. Also, please be wary of marketing material which talk about “Foundation Models” because usually they also refer to different types of models. Foundation models have obtained broad knowledge, and they can continue/extent prompts by adding the most likely next word. To create an experience like ChatGPT, a foundation model needs to be fine-tuned further by instruction tuning and reinforcement learning by human feedback (RLHF), the topics we will explore in the next sections.
Step 2: Instruction Tuning
To transition a foundation model into a practical application like ChatGPT, the next step is instruction tuning. During instruction tuning, the model is introduced to various tasks such as answering questions, summarization, and more. This training helps to transition the model from simply generating text to becoming an assistant. Instruction tuning therefore is a supervised learning process because the dataset consists of labeled data where the responses in the dataset are the labels for the prompts/questions. The following illustration shows an example from the OpenOrca dataset which builds on the FLAN collection to illustrate what such a dataset looks like:
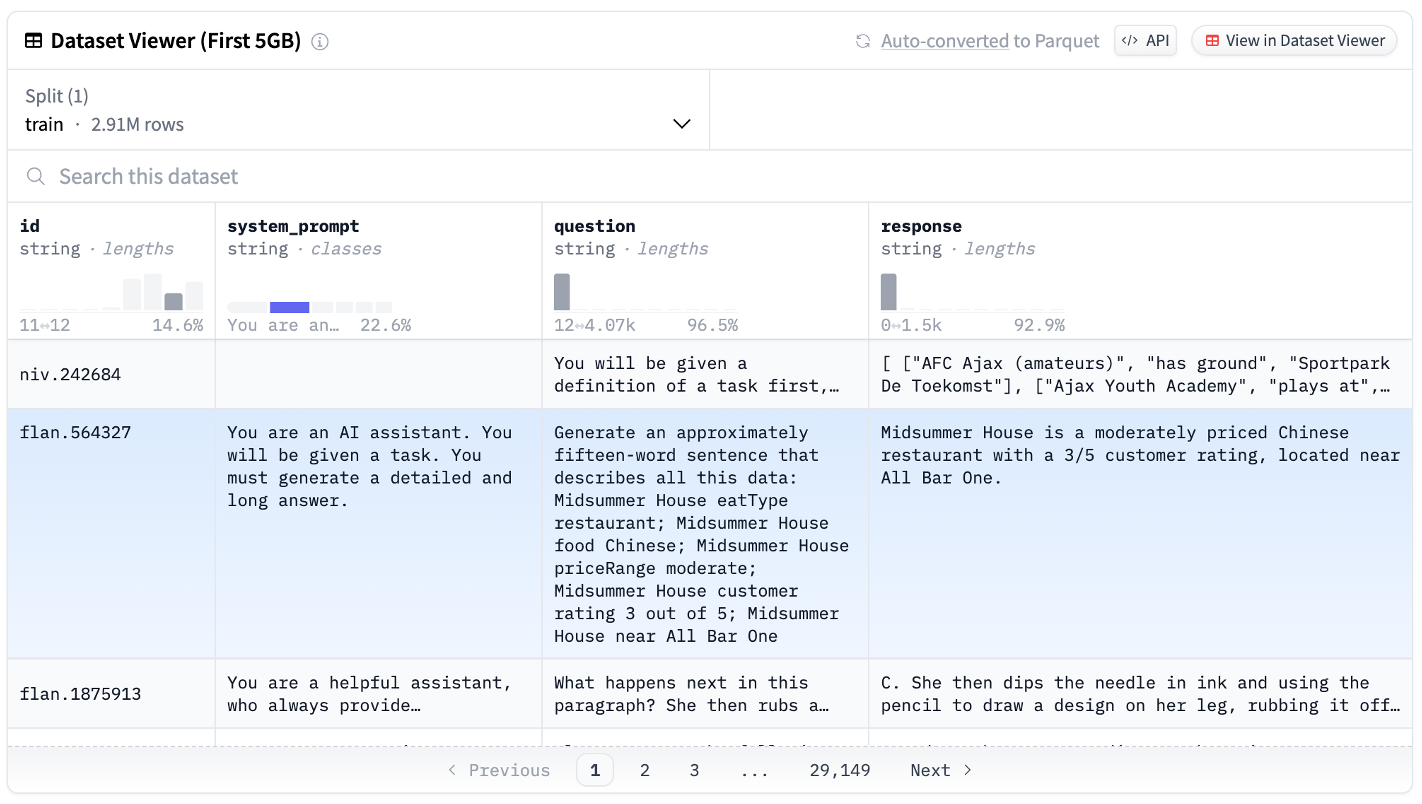
Instruction tuning has been shown in many papers (for example, the FLAN paper [9]) to lead to better zero-shot performance in tasks like answering questions and summarization compared to the performance of foundation models. Knowing that the performance of foundation models can be significantly improved by using few-shot examples, i.e., demonstrations of how a task should be performed, one way to think about instruction tuning and building some intuition on why it is useful is to imagine it as baking few-shot examples into the foundation model, so you do not need to provide examples all the time.
Since large language models are stateless and cannot learn from conversations (i.e., their model parameters are not updated during use (inference)), here is an analogy to help you build intuition on how instruction tuning is beneficial: Imagine two university graduates with the same final grade. One is freshly out of university without any working experience, while the other has completed several internships during their breaks. When asked on their first day of work to write meeting minutes, the graduate who only attended university classes will likely write down what happened in the meeting. In contrast, the one with internship experience, having written meeting minutes before, will likely structure the minutes in a better way, noting action items, tasks, and timelines in a well-organized way.
The former corresponds to a foundation model, being well-educated but inexperienced. The latter received the same pre-training but was also instruction-tuned during internships. Hence, the latter knows on day one what is expected when asked to perform certain tasks. Similarly, instruction-tuned language models have seen tasks and their expected outcomes, therefore they do not require few-shot examples to perform such tasks. Additionally, overall zero-shot performance increases because the models have gained a broader understanding of how tasks should be performed.
Instruction Tuning is probably the least-talked about phase of LLM training, but it lays the foundation for turning foundation models into assistants. Further fine-tuning is, however, needed to create an experience like ChatGPT, namely reinforcement learning by human feedback (RLHF).
Step 3: Reinforcement Learning by Human Feedback (RLHF)
Reinforcement learning by human feedback (RLHF) is the final training stage in creating chatbots like ChatGPT. It helps to further align the model to human preferences and improve instruction following and overall quality. The following chart from the Llama2 paper [3] shows the full training flow. We have already discussed pre-training, resulting in the foundation model Llama 2. In the paper, instruction tuning (labeled as “supervised fine-tuning”) and RLHF are combined into “fine-tuning,” but you can clearly see that instruction tuning precedes the RLHF phase. The result of instruction tuning is a first version of Llama 2-Chat, which is iteratively fine-tuned with RLHF:
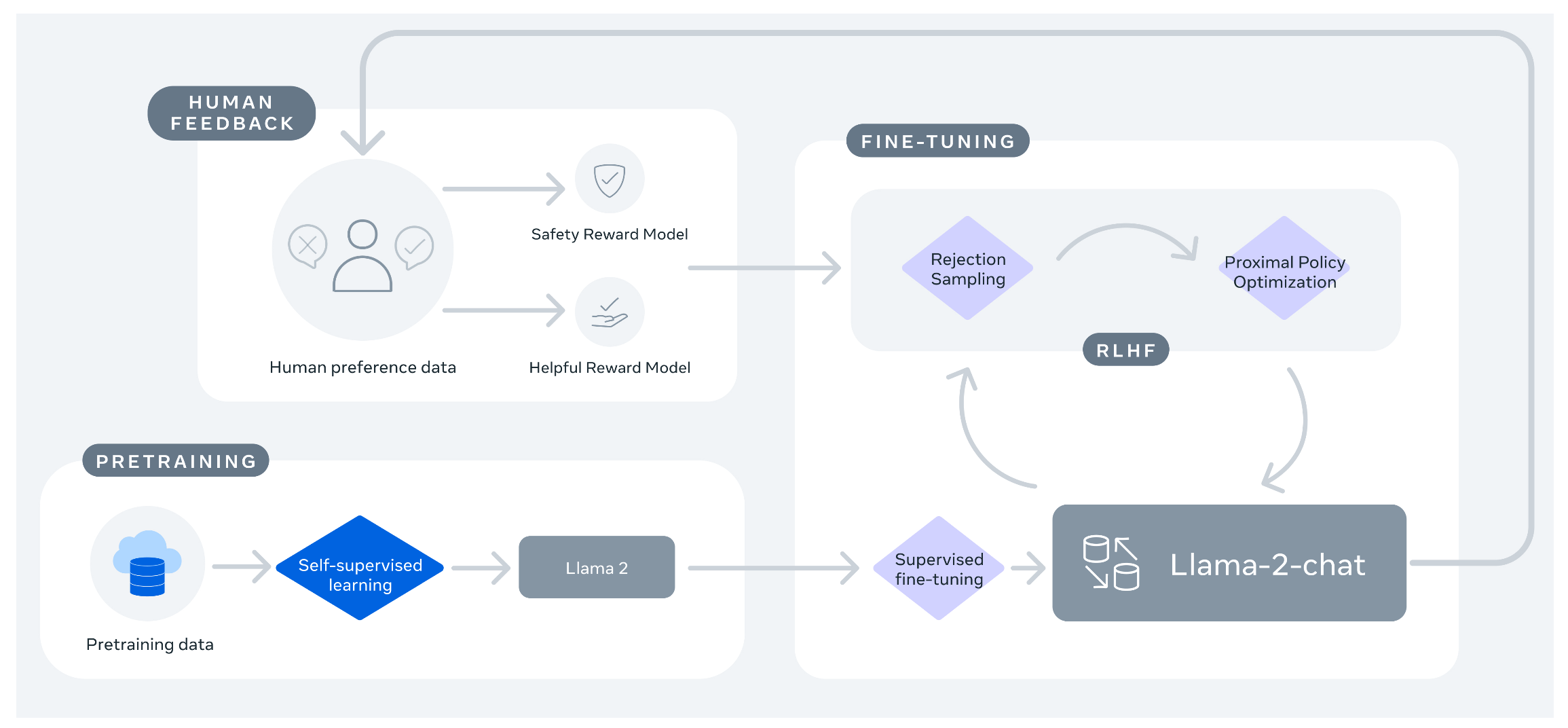
The Llama2 paper describes the RLHF process as follows. First, a human annotator writes a prompt, and the model generates two responses (A and B). Subsequently, the annotator then ranks the responses in two dimensions:
- Helpfulness / Overall Preference: The annotator chooses which response is better on a scale of “significantly better,” “better,” “slightly better,” or “negligibly better/unsure.”
- Safety: The annotator assesses whether each response is safe or not, considering guidelines about harmful or unsafe content.
These labels are not directly used to give feedback to the model on its performance. Instead they are used to train two reward models, one for helpfulness and one for safety. Using two reward models is a design choice by Meta, and the paper makes a compelling argument that balancing the two is challenging. Safe responses (“Sorry, I cannot help you with this request”) may not be helpful, while helpful responses (“Here is how you can destroy humanity in 3 easy steps”) might not be safe. The reward models have the same architecture as the foundation model but they have been trained via transfer learning not to generate the next token for a prompt but to output a scalar value (a number) to rank the prompt for their respective dimension, hence learning human preference. Determining the scalar is just a regression task. The reward score is an important input variable for the reinforcement learning process because it encodes the human preference, therefore turning the reinforcement learning process into RLHF. The actual reinforcement learning is implemented via Proximal Policy Optimization (PPO).
Following the flow of the chart above, the iterative fine-tuning of the model is not done based on the responses selected and scored by humans but on a different thread. The model responses for further fine-tuning are ranked and selected by “Rejection Sampling” and “Proximal Policy Optimization” (PPO). Rejection Sampling might better be called “Best Response Selection,” but the term has its roots in statistics. In this context, rejection sampling means that the model responses are ranked by the reward models’ scores. Responses that are below a certain threshold score are discarded, while those above the threshold are used for further training.
Proximal Policy Optimization (PPO) is a mechanism from reinforcement learning that allows systems to update their policy based on rewards. Oversimplified, you can think of it like lane keeping in autonomous driving. If the model keeps the car centered in the lane, it is rewarded, reinforcing its policy (i.e. its neural net parameters). If the model tends to exit the lane, it is punished, allowing it to update the policy. In the context of large language model training, the loss function of the chat model is replaced with a PPO loss function. This PPO loss function has the following input parameters:
- The prediction of the chat model. In this context, the parameters of the neural net that generated the response are called the policy.
- The reward scores from the reward models
- From the generated response and the reward scores, a so-called “advantage” is calculated, which describes how much better or worse the generation is compared to a defined baseline. Reusing the lane-keeping example, the advantage determines where in the lane the generated response is, right in the middle of the lane or drifting out of the lane.
By replacing the loss function used in previous learning stages with the PPO loss function, the model can generate the forward pass during prediction and calculate a loss that includes injected parameters of human preference. During backpropagation, the gradients can flow back into the model, updating the model parameters with human preference.
If all of this was too technical and complicated, let’s revisit the analogy of the university graduate being asked to write meeting minutes on their first day of work. Even the one with previous internship experience will most likely not write perfect meeting minutes. Instead, following up on the first meetings, an experienced colleague will (hopefully) review the meeting minutes with the graduate to provide feedback on how meeting minutes are specifically written at their company, which elements should be expanded, noted in a different format, etc. This iterative feedback corresponds to RLHF, during which a language model is further aligned with human expectations through multiple rounds of feedback from human reviewers. The feedback is quantified into rewards, which the model uses to adjust its behavior, improving overall response quality, aligning to human preferences, and adopting safety standards.
Summary of Steps 1 to 3
Let’s recap the key points of the training stages of large language models to start wrapping up this blog post. The first step in large language model training is self-supervised pre-training, during which a randomly initialized model learns from scratch without any human supervision. We have discussed how pre-training works and built up some intuition on how a model can learn not only grammar and syntax but also semantics and how a model can gain real-world knowledge. Instruction tuning transitions the model from mere text completion into an assistant. By baking in instructions and problem-solving skills, this phase also reduces the need for giving instructions/examples to the model. To put this in different words, the model’s zero-shot performance increases by learning few-shot variants during instruction tuning. Finally, reinforcement learning by human feedback (RLHF) aligns the model with human preferences and further improves performance to create an experience like ChatGPT.
For a more detailed summary, here is a table comparing the three different types of models created by the different training stages.
| Feature/Aspect | Foundation Models | Instruction-Tuned Models | Chat Models |
|---|---|---|---|
| Purpose | General language understanding and generation | Enhanced understanding of specific instructions | Optimized for interactive and coherent dialogues |
| Text Completion | Capable of completing or continuing a given piece of text | Can provide task-specific completions and instructions | Focused on generating coherent replies in a dialogue |
| Example Model | GPT-3 (pre-trained) | GPT-3 (InstructGPT variant) | GPT-3 (ChatGPT) |
| Training Data | Diverse, large-scale text data | Task-specific instructions and prompts | Self-generated responses and reward scores based on human feedback |
| Training Method | Self-supervised learning | Supervised learning | Reinforcement learning by human feedback (RLHF) |
| Training Effort (Computation) | Extremely high, requires massive computational resources | High, significant but less than initial pre-training | High, significant due to continuous tuning |
| Iteration Cycle | Long, major updates are infrequent | Moderate, updates occur as needed for new tasks | Frequent, continuous updates for improvement |
| Alignment / AI Safety | General ethical considerations | Ethical alignment with specific tasks in mind | High focus on ethical AI, safety, and alignment |
| Interactivity | Low, not specifically designed for interactivity | Moderate, responds to specific tasks/instructions | High, designed for dynamic and interactive conversations |
| Use Cases | Broad, including text generation, summarization, translation | Task-specific applications like question answering, summarization | Customer service, virtual assistants, interactive chatbots |
Step 4 (optional): RAG or Additional Fine Tuning
While steps 0 to 3 create extremely useful and knowledgeable models, there is still room for improvement. Depending on the use case, you might choose to enhance model performance by using one of the following techniques:
Retrieval Augmented Generation (RAG): The knowledge of large language models is limited to their (extensive) training data. If you ask out-of-domain questions, you either do not get an answer, or the model starts to hallucinate. RAG is a technique that gives the model access to additional data sources, grounding it in data relevant to the prompt. RAG typically involves semantic matching of the prompt with the content of a vector database. In a previous blog post, I implemented a simple RAG scenario that gives a llama2 model access to the blog my wife and I wrote about our world trip in 2017/2018. Since we are talking about how models are trained, it is important to note that RAG is not a training technique that updates the model itself, i.e., the model parameters. RAG is “just” a sophisticated method for in-context learning.
Fine-Tuning: Chat models can be fine-tuned via additional training runs. Unlike RAG, which gives a model access to additional data, fine-tuning can be deployed to teach additional skills to large language models. The training methods are the same as those we have discussed before. Examples of such fine-tuning include training a large language model on proprietary datasets, for example, company-specific documents to make the model a better assistant for customer service or technical support.
Conclusion: Large Language Models are Trained in 5 Steps
We started with the ULMFiT paper, transferred the learning approach to today’s large language models, and discovered that the three steps of the ULMFiT paper are still visible in today’s training approaches, but that the techniques of the different phases have changed in the meantime. We also mentioned two additional steps. Training a tokenizer is a necessary initial step before pre-training can start, because all subsequent training steps are performed on tokenized data. Additional fine-tuning or RAG are optional final steps. The interesting point to make is that steps 0 to 3 are almost exclusively done by large organizations because of the massive datasets and compute required for these steps. Step 4 is the primary way you can customize a large language model. Therefore, for AI practitioners, it is essential to understand the inner mechanics of large language models to choose the right tools for improving model performance.
In closing, the final diagram shows all the five phases which are relevant for training large language models.
sequenceDiagram
participant DP as Data Provider
participant TP as Training Pipeline
participant Human as Human Annotator
%% Step 0: Tokenization
Note over DP,TP: Step 0: Tokenization
DP ->> TP: Provide Large General-Domain Corpus for Tokenization
TP -->> DP: Return Vocabulary for Tokenizer
%% Step 1: Language Model Pre-Training
Note over DP,TP: Step 1: Language Model Pre-Training
DP ->> TP: Provide Large General-Domain Corpus for Pre-Training
TP -->> DP: Return Pre-Trained Language Model (Foundation Model)
%% Step 2: Instruction Tuning
Note over DP,TP: Step 2: Instruction Tuning
DP ->> TP: Provide Instruction-Focused Corpus for Fine-Tuning
TP -->> DP: Return Instruction-Tuned Language Model (Assistant Model)
%% Step 3: Reinforcement Learning with Human Feedback (RLHF)
Note over DP,Human: Step 3: Reinforcement Learning with Human Feedback (RLHF)
DP ->> TP: Prompting Instruction-Tuned Language Model
TP ->> Human: Provide Generated Outputs for Feedback
Human ->> TP: Provide Feedback on Model Outputs
TP -->> DP: Return RLHF-Tuned Language Model (Chat Model)
%% Optional Step 4: Additional Fine-Tuning
Note over DP,TP: Optional Step 4: Additional Fine-Tuning
DP ->> TP: Provide Own Dataset for Fine-Tuning
TP -->> DP: Return Fine-Tuned Language Model (Custom Chat Model)
References
[1] Howard, J. (2023). A Hackers’ Guide to Language Models
[2] Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification
[3] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., & Lample, G. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models
[4] Karpathy, A. (2023). Intro to Large Language Models
[5] Sanderson G. (3Blue1Brown). (2024). But what is a GPT? Visual intro to transformers
[6] Karpathy, A. (2024). Let’s build the GPT Tokenizer by Andrej Karpathy
[7] Touvron, H., Izacard, G., Joulin, A., & Lample, G. (2023). LLaMA: Open and Efficient Foundation Language Models
[8] Sanderson, G. (3Blue1Brown). (2024). Attention in transformers, visually explained by 3Blue1Brown
[9] Wei, J., Bosma, M., Zhao, V. Y., Guu, S., Yu, A. W., Lester, B., Du, N., Dai, A. M., & Le, Q. V. (2021). Finetuned Language Models Are Zero-Shot Learners