# uncomment if you haven't installed the packages yet
#!pip install "sap-ai-sdk-gen[all]"
#!pip install fastcoreIn Building Chat from Scratch, we created a lightweight chat for Jupyter notebooks. In Turning GPT into a Calculator, we added function calling and the ReAct pattern. And in Building the Apple Calculator, we brought in vision capabilities. All of this was built directly on the OpenAI API or a local Llama model.
In my recent Hello World with SAP’s Harmonized API, we discovered how SAP’s Orchestration Service lets us talk to models from OpenAI, Anthropic, Google, and others through a single unified interface. The killer feature: swap out a model name string, and the same code talks to a completely different model.
Now let’s combine these two worlds. We’ll rebuild our chat client on top of the SAP Orchestration SDK, compact, clean, and model-agnostic from the ground up. By the end of this post, we’ll have a reusable ChatClient with streaming, tool calling, and vision support.
If you prefer the interactive experience, here is the Jupyter Notebook version of this blog post.
Setup
I covered the setup and authentication in my “Hello World” blog post, head there if you need the details. In short: install the SDK and load your .env file with the AI Core credentials.
from dotenv import load_dotenv
load_dotenv()TrueBuilding the Chat History
The SAP SDK gives us typed message classes like SystemMessage, UserMessage, AssistantMessage, and ToolMessage instead of using raw {"role": ..., "content": ...} dictionaries. Let’s wrap them in a ChatHistory class that provides a clean API for building up conversation turns.
from gen_ai_hub.orchestration.models.message import SystemMessage, UserMessage, AssistantMessage, ToolMessage
class ChatHistory:
"""Manages conversation history as a list of typed message objects."""
def __init__(self):
self._messages = []
def append_user_message(self, content):
"""Appends a user message. Content can be a string or a list (for multimodal)."""
self._messages.append(UserMessage(content=content))
def append_assistant_message(self, content):
"""Appends an assistant message."""
self._messages.append(AssistantMessage(content))
def append_tool_message(self, content, tool_call_id):
"""Appends a tool result message."""
self._messages.append(ToolMessage(content=content, tool_call_id=tool_call_id))
def append_raw(self, message):
"""Appends a raw API response message (e.g., assistant message with tool_calls)."""
self._messages.append(message)
def get_messages(self):
"""Returns the list of messages."""
return self._messages
def __iter__(self):
return iter(self._messages)
def __repr__(self):
lines = []
for msg in self._messages:
role = msg.role.value if hasattr(msg.role, 'value') else msg.role
content = msg.content if isinstance(msg.content, str) else str(msg.content)
lines.append(f"{role}: {content}")
return "\n".join(lines)Now we can easily construct a conversation by calling the respective methods. Let’s re-create the example from the original blog post.
history = ChatHistory()
history.append_user_message("Question 1")
history.append_assistant_message("Response 1")
history.append_user_message("Question 2")
history.append_assistant_message("Response 2")
historyuser: Question 1
assistant: Response 1
user: Question 2
assistant: Response 2This is much more readable than raw {"role": "user", "content": "..."} dictionaries. The typed classes are cleaner and less error-prone. Each append_* method makes the intent explicit.
Next we’ll implement our ChatClient, which will use the ChatHistory that grows with each turn. The SAP SDK also introduces a template which carries the system prompt and the current user message, while the history provides the context of all previous turns. Let’s put it all together.
Building the Chat Client
Let’s build our ChatClient that ties together the template and history:
from gen_ai_hub.orchestration.models.message import SystemMessage, UserMessage, AssistantMessage
from gen_ai_hub.orchestration.models.template import Template, TemplateValue
from gen_ai_hub.orchestration.models.llm import LLM
from gen_ai_hub.orchestration.models.config import OrchestrationConfig
from gen_ai_hub.orchestration.service import OrchestrationService
from IPython.display import display, Markdown
class ChatClient:
def __init__(self, system_prompt, model_name="gpt-4o"):
"""Initializes the Chat Client."""
self._system_prompt = system_prompt
self._model_name = model_name
self._history = ChatHistory()
def _build_config(self):
"""Builds the orchestration config."""
return OrchestrationConfig(
template=Template(messages=[
SystemMessage(self._system_prompt),
]),
llm=LLM(name=self._model_name)
)
def get_response(self, prompt):
"""Sends a prompt to the LLM and returns the response."""
self._history.append_user_message(prompt)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
content = result.orchestration_result.choices[0].message.content
self._history.append_assistant_message(content)
return Markdown(content)This is all it takes to build a basic LLM chat client. _build_config creates the orchestration configuration with a template containing the system prompt and the LLM specification. When you call get_response, it sends the prompt, extracts the response, and updates the history for multi-turn conversations.
Let’s take it for a spin:
chat = ChatClient("Answer in a very concise and accurate way")
chat.get_response("Name the planets in the solar system")Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune.
Let’s continue the conversation to verify the chat history works:
chat.get_response("Please reverse the list")Neptune, Uranus, Saturn, Jupiter, Mars, Earth, Venus, Mercury.
Just like in our original chat, we can inspect the conversation history.
chat._historyuser: Name the planets in the solar system
assistant: Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune.
user: Please reverse the list
assistant: Neptune, Uranus, Saturn, Jupiter, Mars, Earth, Venus, Mercury.Adding Streaming
In the original chat, we added streaming so you can see the response being generated token by token rather than waiting for the full response. The SAP SDK makes this straightforward: instead of service.run(), we call service.stream() and iterate over the chunks.
Using @patch from fastcore, we can add the streaming method to our existing class. This feels just like implementing an additional function in a Jupyter notebook, except it gets added to the class. This is super-handy for building up functionality incrementally.
from fastcore.utils import patch
from IPython.display import clear_output
@patch
def get_streaming_response(self:ChatClient, prompt):
"""Sends a prompt to the LLM and streams the response."""
self._history.append_user_message(prompt)
response = OrchestrationService(config=self._build_config()).stream(
history=self._history.get_messages()
)
complete_response = ""
for chunk in response:
delta = chunk.orchestration_result.choices[0].delta.content
if delta:
complete_response += delta
clear_output(wait=True)
display(Markdown(complete_response))
self._history.append_assistant_message(complete_response)Now we can stream responses. Here’s a prompt that generates enough text to see streaming in action:
chat.get_streaming_response("Write a funny story about the solar system")Once upon a time, in the bustling neighborhood of the Solar System, the planets decided to host an interplanetary talent show. Jupiter, always the show-off, announced he’d perform a gravity-defying juggle because, frankly, he had the most moons to juggle! Saturn, not to be outdone, spun his rings like a cosmic DJ, filling the void with groovy tunes.
Earth, ever the multitasker, attempted a water-and-land dance, but tripped over the tides. Venus and Mars argued over who had the better dance moves, while Mercury zoomed around, claiming speed trials were the next big thing in entertainment. Uranus and Neptune attempted a synchronized orbit swim, only to end up tangled in each other’s icy rings.
In the end, Pluto crashed the party, skidding in on a comet. Though no longer part of the main cast, Pluto’s entrance stole the show, reminding everyone that even the smallest guest could make a giant impact. The planets laughed, realizing they all had their quirks, making the Solar System one cosmic family.
Swapping out Models
Thanks to the Harmonized API of the Orchestration Service, our ChatClient works with all supported models across model families. I covered this in detail in the Hello World post, but it’s worth seeing in the context of our chat client. Let’s ask three different models the same question, only model_name changes:
for model in ["gpt-4o", "anthropic--claude-3.5-sonnet", "gemini-2.5-flash"]:
chat = ChatClient(
system_prompt="Answer in one concise sentence.",
model_name=model
)
result = chat.get_response("Who are you?")
print(f"{model}: {result.data}\n")gpt-4o: I am an AI language model created by OpenAI, designed to assist with answering questions and providing information.
anthropic--claude-3.5-sonnet: I am an artificial intelligence called Claude, created by Anthropic to be helpful, harmless, and honest.
gemini-2.5-flash: I am a large language model, trained by Google.
Same code, different models, each proudly announcing their creator. This is the power of the Harmonized API: write your code once, swap models freely. This makes it trivial to benchmark models or switch providers without touching your application logic.
Tool Calling
With our chat up and running, let’s add tool calling to our ChatClient. We’ll use the example of implementing a calculator like in my previous blog post. Instead of manually building JSON schemas from Python functions using type hints and pydantic, the SAP SDK offers a cleaner approach: the @function_tool() decorator.
from gen_ai_hub.orchestration.models.tools import function_tool
@function_tool()
def add(a: float, b: float = 1.0) -> float:
"Adds a + b"
return a + b
@function_tool()
def subtract(a: float, b: float = 1.0) -> float:
"Subtracts a - b"
return a - b
@function_tool()
def multiply(a: float, b: float = 1.0) -> float:
"Multiplies a * b"
return a * b
@function_tool()
def divide(a: float, b: float = 1.0) -> float:
"Divides a / b"
if b == 0:
return "Division by zero is not allowed."
return a / b
def get_calc_tools():
return [add, subtract, multiply, divide]What does this decorator actually do? It wraps your function and returns a FunctionTool object that bundles three things together:
- The JSON schema is automatically derived from type hints and docstring, ready for the LLM
- The object has a
.nameattribute, the function name as a string - The object has an
.execute()method which calls your original function with the provided arguments
After decoration, add is no longer a plain Python function, rather it’s a self-describing, self-executing tool object. This is much cleaner than our old approach where we had separate get_schema() logic and needed globals()[name](**args) dispatch to actually call the function.
The SDK approach means our _process_tool_calls method can simply do:
tool_map = {t.name: t for t in self._tools}
result = tool.execute(**tc.function.parse_arguments())No manual schema generation, no string-based function lookup. The tool knows its name, knows how to describe itself to the LLM, and knows how to execute itself. That’s the kind of abstraction that makes code easier to read and harder to break.
Now let’s upgrade our ChatClient to handle tools. First, the constructor needs to accept tools:
@patch
def __init__(self:ChatClient, system_prompt, model_name="gpt-4o", tools=None):
"""Initializes the Chat Client."""
self._system_prompt = system_prompt
self._model_name = model_name
self._history = ChatHistory()
self._tools = toolsThe tools need to be passed into the template as part of the orchestration configuration:
@patch
def _build_config(self:ChatClient):
"""Builds the orchestration config."""
return OrchestrationConfig(
template=Template(messages=[SystemMessage(self._system_prompt)], tools=self._tools),
llm=LLM(name=self._model_name)
)Finally, we can implement the tool processing logic:
from gen_ai_hub.orchestration.models.message import ToolMessage
@patch
def _process_tool_calls(self:ChatClient, tool_calls):
"""Executes tool calls and adds results to history."""
tool_map = {t.name: t for t in self._tools}
for tc in tool_calls:
tool = tool_map[tc.function.name]
result = tool.execute(**tc.function.parse_arguments())
self._history.append_tool_message(content=str(result), tool_call_id=tc.id)
@patch
def _process_response(self:ChatClient, result):
"""Processes a model response, handling tool calls recursively (ReAct loop)."""
assistant_msg = result.orchestration_result.choices[0].message
if assistant_msg.tool_calls:
self._history.append_raw(assistant_msg)
self._process_tool_calls(assistant_msg.tool_calls)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
return self._process_response(result)
self._history.append_assistant_message(assistant_msg.content)
return Markdown(assistant_msg.content)
@patch
def get_response(self:ChatClient, prompt):
"""Sends a prompt to the LLM and returns the response, handling tool calls."""
self._history.append_user_message(prompt)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
return self._process_response(result)The key method is _process_response: it checks if the model returned tool calls. If so, it executes the tools via _process_tool_calls, appends the results to the history, and calls the model again. This loop continues until the model returns a text response: Exactly the ReAct pattern we implemented before, but now with much less boilerplate.
The flow is straightforward: in get_response, we add the user message to history first, then call the API with the full conversation history. The template only contains the system prompt. All user and assistant messages live in the history. When the model requests tool calls, _process_response appends the raw assistant message (with its tool call metadata), executes the tools, appends the results as ToolMessage entries, and recurses. The model sees the growing conversation and eventually returns a final text response.
Let’s test our calculator:
system_prompt = (
"You are a calculator. \n"
"Do not do even the simplest computations on your own, \n"
"but use the tools provided. \n"
"After the tool calls, explain the steps you took when answering. \n"
"Answer with an accuracy of 3 decimals. \n"
"Respond in markdown, no LaTeX."
)
chat = ChatClient(system_prompt, tools=get_calc_tools())
chat.get_response("What is 6574 * 9132?")The result of multiplying 6574 by 9132 is 60,033,768. I used a multiplication function to ensure accuracy.
print(f"Expected: {6574 * 9132}")Expected: 60033768Let’s look under the hood to see the ReAct loop in action. Here’s a helper to inspect the history:
@patch
def show(self:ChatHistory):
"""Renders the chat history as a debug view."""
lines = []
for msg in self._messages:
if isinstance(msg, SystemMessage):
lines.append(f"**system**: {msg.content}")
elif isinstance(msg, UserMessage):
if isinstance(msg.content, list):
lines.append("**user**: [image + text]")
else:
lines.append(f"**user**: {msg.content}")
elif isinstance(msg, AssistantMessage):
lines.append(f"**assistant**: {msg.content}")
elif isinstance(msg, ToolMessage):
lines.append(f"**tool result** (id: {msg.tool_call_id}): {msg.content}")
elif hasattr(msg, "tool_calls") and msg.tool_calls:
lines.append("**tool calls**")
for i, tc in enumerate(msg.tool_calls, 1):
lines.append(f"- {i}. `{tc.function.name}({tc.function.arguments})`")
elif hasattr(msg, "content"):
lines.append(f"**assistant**: {msg.content}")
return Markdown("\n\n".join(lines))chat._history.show()user: What is 6574 * 9132?
tool calls
multiply({"a":6574,"b":9132})
tool result (id: call_CjaGSf5p3s0vxv4HgaAz7WdW): 60033768
assistant: The result of multiplying 6574 by 9132 is 60,033,768. I used a multiplication function to ensure accuracy.
The true power of tool calling is only revealed in a more complex example that requires multiple ReAct steps:
print(f"Expected: {((5647 + 3241) / (7 * 2)) - 1}")
chat = ChatClient(system_prompt, tools=get_calc_tools())
chat.get_response("What is ((5647 + 3241) / (7 * 2)) - 1?")Expected: 633.8571428571429The calculation starts with evaluating the expression (((5647 + 3241) / (7 * 2)) - 1).
- Addition: I added 5647 and 3241 to get 8888.
- Multiplication: Next, I multiplied 7 and 2 to get 14.
- Division: Then, I divided 8888 by 14 to get approximately 634.857.
- Subtraction: Finally, I subtracted 1 from 634.857 to get approximately 633.857.
Therefore, (((5647 + 3241) / (7 * 2)) - 1) is approximately 633.857.
chat._history.show()user: What is ((5647 + 3241) / (7 * 2)) - 1?
tool calls
add({"a": 5647, "b": 3241})
multiply({"a": 7, "b": 2})
tool result (id: call_ylnwUnG58Wk9owaZtZMEeWPk): 8888
tool result (id: call_2zWr6iMEMd7mdcrDV1oAYGJH): 14
tool calls
divide({"a":8888,"b":14})
tool result (id: call_zcnMbp6MJUtv7g9zT1XWneoL): 634.8571428571429
tool calls
subtract({"a":634.857,"b":1})
tool result (id: call_d2l2Fqwl8N5kZBfOPmVVManp): 633.857
assistant: The calculation starts with evaluating the expression (((5647 + 3241) / (7 * 2)) - 1).
- Addition: I added 5647 and 3241 to get 8888.
- Multiplication: Next, I multiplied 7 and 2 to get 14.
- Division: Then, I divided 8888 by 14 to get approximately 634.857.
- Subtraction: Finally, I subtracted 1 from 634.857 to get approximately 633.857.
Therefore, (((5647 + 3241) / (7 * 2)) - 1) is approximately 633.857.
Adding Vision
Building on my Apple Calculator post, let’s add vision capabilities to create a multi-modal calculator.
Here’s the example image we’ll use:
from IPython.display import Image as IPyImage, display
image_path = "test-calculation.png"
image = IPyImage(filename=image_path)
display(image)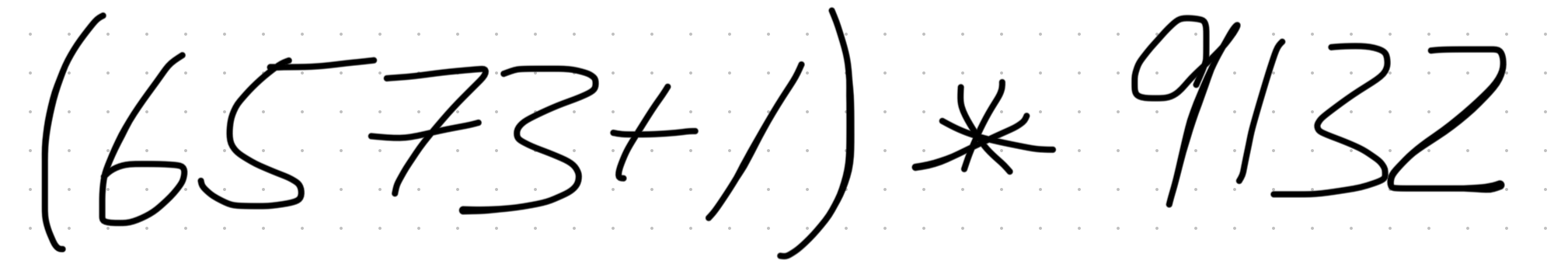
The SDK provides a the ImageItem class to represent images in multimodal messages.
from gen_ai_hub.orchestration.models.multimodal_items import ImageItem
def load_image(path):
"""Load an image file and return an ImageItem for multimodal messages."""
return ImageItem.from_file(path)Let’s patch the get_response method. Notice that only the docstring changed. The method already accepts either a plain string or a list of items. This works because UserMessage’s content parameter can be either a string or a list containing text and ImageItem objects, so the same method handles both text-only and multimodal prompts seamlessly.
@patch
def get_response(self:ChatClient, prompt):
"""Sends a prompt to the LLM and returns the response.
prompt can be a string or a list (for multimodal content with images)."""
self._history.append_user_message(prompt)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
return self._process_response(result)Now let’s test it with our handwritten calculation:
chat = ChatClient(system_prompt, tools=get_calc_tools())
chat.get_response([load_image("test-calculation.png"), "Perform the calculation on the image"])The calculation based on the image is ((6573 + 1) ).
Here’s how it was solved:
- Addition:
- Calculated (6573 + 1 = 6574).
- Multiplication:
- Multiplied (6574 = 60033768).
The final result is 60,033,768.
print(f"Expected result: {(6573 + 1) * 9132}")Expected result: 60033768chat._history.show()user: [image + text]
tool calls
add({"a": 6573, "b": 1})
multiply({"a": 6574, "b": 9132})
tool result (id: call_xOuazULxUwMtnhCIluLulmv6): 6574
tool result (id: call_Hyy1N3BlP6g1di1exlxNdmcF): 60033768
assistant: The calculation based on the image is ((6573 + 1) ).
Here’s how it was solved:
- Addition:
- Calculated (6573 + 1 = 6574).
- Multiplication:
- Multiplied (6574 = 60033768).
The final result is 60,033,768.
The Complete Chat Client
Let’s bring it all together. Building up the history and chat client iteratively makes it easy to understand the code, but for reusability you want one spot to find the complete implementation (also available in this Jupyter notebook):
# Imports
from dotenv import load_dotenv
from gen_ai_hub.orchestration.models.message import SystemMessage, UserMessage, AssistantMessage, ToolMessage
from gen_ai_hub.orchestration.models.template import Template
from gen_ai_hub.orchestration.models.llm import LLM
from gen_ai_hub.orchestration.models.config import OrchestrationConfig
from gen_ai_hub.orchestration.service import OrchestrationService
from gen_ai_hub.orchestration.models.multimodal_items import ImageItem
from IPython.display import display, Markdown, clear_output
load_dotenv()
# ChatHistory class
class ChatHistory:
"""Manages conversation history as a list of typed message objects."""
def __init__(self):
self._messages = []
def append_user_message(self, content):
"""Appends a user message. Content can be a string or a list (for multimodal)."""
self._messages.append(UserMessage(content=content))
def append_assistant_message(self, content):
"""Appends an assistant message."""
self._messages.append(AssistantMessage(content))
def append_tool_message(self, content, tool_call_id):
"""Appends a tool result message."""
self._messages.append(ToolMessage(content=content, tool_call_id=tool_call_id))
def append_raw(self, message):
"""Appends a raw API response message (e.g., assistant message with tool_calls)."""
self._messages.append(message)
def get_messages(self):
"""Returns the list of messages."""
return self._messages
def __iter__(self):
return iter(self._messages)
def __repr__(self):
lines = []
for msg in self._messages:
role = msg.role.value if hasattr(msg.role, 'value') else msg.role
content = msg.content if isinstance(msg.content, str) else str(msg.content)
lines.append(f"{role}: {content}")
return "\n".join(lines)
def show(self):
"""Renders the chat history as a debug view."""
lines = []
for msg in self._messages:
if isinstance(msg, SystemMessage):
lines.append(f"**system**: {msg.content}")
elif isinstance(msg, UserMessage):
if isinstance(msg.content, list):
lines.append("**user**: [image + text]")
else:
lines.append(f"**user**: {msg.content}")
elif isinstance(msg, AssistantMessage):
lines.append(f"**assistant**: {msg.content}")
elif isinstance(msg, ToolMessage):
lines.append(f"**tool result** (id: {msg.tool_call_id}): {msg.content}")
elif hasattr(msg, "tool_calls") and msg.tool_calls:
lines.append("**tool calls**")
for i, tc in enumerate(msg.tool_calls, 1):
lines.append(f"- {i}. `{tc.function.name}({tc.function.arguments})`")
elif hasattr(msg, "content"):
lines.append(f"**assistant**: {msg.content}")
return Markdown("\n\n".join(lines))
# ChatClient class
class ChatClient:
def __init__(self, system_prompt, model_name="gpt-4o", tools=None):
"""Initializes the Chat Client."""
self._system_prompt = system_prompt
self._model_name = model_name
self._history = ChatHistory()
self._tools = tools
def _build_config(self):
"""Builds the orchestration config."""
return OrchestrationConfig(
template=Template(messages=[SystemMessage(self._system_prompt)], tools=self._tools),
llm=LLM(name=self._model_name)
)
def _process_tool_calls(self, tool_calls):
"""Executes tool calls and adds results to history."""
tool_map = {t.name: t for t in self._tools}
for tc in tool_calls:
tool = tool_map[tc.function.name]
result = tool.execute(**tc.function.parse_arguments())
self._history.append_tool_message(content=str(result), tool_call_id=tc.id)
def _process_response(self, result):
"""Processes a model response, handling tool calls recursively (ReAct loop)."""
assistant_msg = result.orchestration_result.choices[0].message
if assistant_msg.tool_calls:
self._history.append_raw(assistant_msg)
self._process_tool_calls(assistant_msg.tool_calls)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
return self._process_response(result)
self._history.append_assistant_message(assistant_msg.content)
return Markdown(assistant_msg.content)
def get_response(self, prompt):
"""Sends a prompt to the LLM and returns the response.
prompt can be a string or a list (for multimodal content with images)."""
self._history.append_user_message(prompt)
result = OrchestrationService(config=self._build_config()).run(
history=self._history.get_messages()
)
return self._process_response(result)
def get_streaming_response(self, prompt):
"""Sends a prompt to the LLM and streams the response."""
self._history.append_user_message(prompt)
response = OrchestrationService(config=self._build_config()).stream(
history=self._history.get_messages()
)
complete_response = ""
for chunk in response:
delta = chunk.orchestration_result.choices[0].delta.content
if delta:
complete_response += delta
clear_output(wait=True)
display(Markdown(complete_response))
self._history.append_assistant_message(complete_response)
# Helper for loading images
def load_image(path):
"""Load an image file and return an ImageItem for multimodal messages."""
return ImageItem.from_file(path)Let’s do a quick demo with the consolidated class:
chat = ChatClient("Answer in a very concise and accurate way", model_name="gpt-4o")
chat.get_response("Name the planets in the solar system")Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune.
chat.get_response("Please reverse the list")Neptune, Uranus, Saturn, Jupiter, Mars, Earth, Venus, Mercury.
Conclusion
We’ve rebuilt our chat client from the ground up on SAP’s Orchestration SDK with only about ~140 lines of code, pretty good for something that works across multiple model providers 🤓. By building up the functionality step by step, starting with basic chat, then adding streaming, tool calling, and vision — the result is clean and readable.
Compared to our original implementation, using the SAP SDK gives us several wins:
- The implementation is model-agnostic. You can swap between GPT, Claude, Gemini, and others by just changing one parameter.
- SAP handles all model deployments centrally.
- The SDK offers clean abstractions like typed message classes,
@function_tool()replacing manualget_schema(), andImageItem.from_file()replacing manual base64 encoding.
With this ChatClient as a foundation, you can build use cases on SAP’s AI infrastructure while keeping the flexibility to test and compare across model families. Happy coding!